
GPU超越了CPU。这也意味着,在臆测鸿沟,专用臆测击败了通用臆测。然则,尽管专用臆测的上风日益彰着,仍有一部分初创公司坚握走通用臆测的谈路,力求通过翻新冲破刻下架构的瓶颈,从头界说处理器的改日。在这个日益分化的臆测期间,通用臆测是否依然有契机与专用臆测一较上下?一些唯利是图的初创公司正在参加巨资和大宗的研发力量果肉系列,试图通过开发全新的通用处理器架构来挑战现存思色。
通用处理器的黄金期间
回归夙昔,通用处理器(CPU)曾在臆测鸿沟垄断了数十年。在70年代到90年代,CPU曾是简直悉数臆测任务的主力。
1971年,英特尔发布了4004处理器,这是寰球上第一款商用微处理器,瑰丽着臆测机本领的一个新纪元。随后,英特尔在1974年发布的 8080 处理器,以过甚后续的 x86 架构,为个东谈主臆测机(PC)提供了刚劲的处理才调。
1981年,IBM个东谈主臆测机(IBM PC)的发布,将基于 x86 架构的通用处理器推向了群众阛阓。
进入1990年代,跟着互联网的崛起和臆测需求的千般化,Intel 和 AMD 等公司不绝股东 x86 架构 的发展,通用处理器的阛阓份额不休扩大。英特尔的 Pentium 处理器系列(1993年推出)瑰丽着高性能臆测的到来。此外,90年代的企业级处事器和数据中心也脱手大宗摄取基于 x86 架构的通用处理器。这一时期,通用处理器不仅在桌面和办公应用中占据主导地位,也冉冉成为处事器、数据中心以及高性能臆测(HPC)鸿沟的主力。
从 2000年代后期脱手,跟着 GPU 和专用加速器(如 TPU、FPGA)的崛起,臆测界的天平脱手发生歪斜。
进入AI期间,臆测需求呈现出爆炸式增长。深度学习等AI算法对臆测资源的需求远远杰出了传统应用。GPU凭借其高度并行的架构,在考试和推理大范围神经采集方面发扬出色,成为了AI考试的“标配”。这一时期,GPU在图形处理、科学臆测以及机器学习等鸿沟的发扬,冉冉超越了传统的CPU。与此同期,各式专用集成电路(ASIC)也在不休泄露,针对特定AI算法进行优化,进一步晋升了臆测恶果。
尽管GPU和ASIC在特定鸿沟的上风突出彰着,但它们也有弗成忽视的污点。起初,GPU 和 ASIC 是专为某些特定任务假想的,败落通用性和天真性。要是面对复杂的臆测任务或需要多种臆测才调的应用,GPU 和 ASIC 就显得不那么高效。此外,GPU 和 ASIC 的开发和分娩资本较高,且其硬件架构不时与现存的臆测环境不兼容,这使得大宗企业在进行硬件更新时濒临着较高的本领门槛和经济资本。
恰是这些缺口,令一些初创公司找到了弯谈超车的效用点。在AI期间的快速浸礼下,数据中心的挑战和痛点愈发突显:居高不下的功耗、较低的处事器运用率以及难以跟上需求的处理器性能。
初创公司Tachyum:
各式PU大乱炖,能成吗?
初创公司Tachyum漠视了一种斗胆的愿景:将超大范围数据中心飘浮为的确的通用臆测中心。
他们是如何作念的呢?Tachyum推出了一种新式通用处理器,将CPU、GPGPU 和 TPU的功能结伴到单个单片斥地中,无需不菲且耗电的加速器,而是通过使用与软件可组合性和处事器资源的动态从头分派相一致的绵薄同质软件模子来最大规矩地提高运用率,以此来满足云和 HPC/AI 责任负载的高需求。该架构速率更快、功耗镌汰10倍、资本仅为竞争居品的 1/3。
下图是早期(2022年)Tachyum公司对Prodigy架构的构念念,它集成了128个自界说的 64 位 CPU 中枢,运行频率最高可达 5.7 GHz,有十六个DDR5内存适度器,撑握最高DDR5-7200,和64条PCIe 5.0 通谈。CPU、内存适度器和I/O通过Tachyum自界说假想的10 Tbps非梗阻全网状互联采集连续在一齐。Prodigy提供了一种顶端的“系统芯片”假想,均衡了高性能的CPU 中枢、内存、I/O和互联子系统。
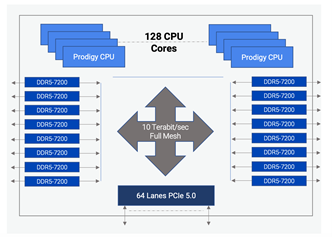
Prodigy斥地架构图(起头:Tachyum Prodigy架构白皮书,2022)
Prodigy摄取独到的“半芯片(half-chip)”假想,使得这款128核的斥地不错算作两个孤独的64核斥地责任,每个斥地配备8个DDR5内存适度器、32条PCIe 5.0通谈、孤独的电源平面,并具备单独启动的才调。这带来了多个平允。起初,从客户的角度来看,两个功能斥地不错部署在一个单一封装中,检朴资本、板空间和功耗,并为系统和板假想者提供天真性。从运营的角度来看,这种架构为Tachyum提供了更高的64核芯片良率。要是“北半部分”出现问题,不错将芯片旋转180度,“南半部分”将成为平淡责任的 64 核斥地。
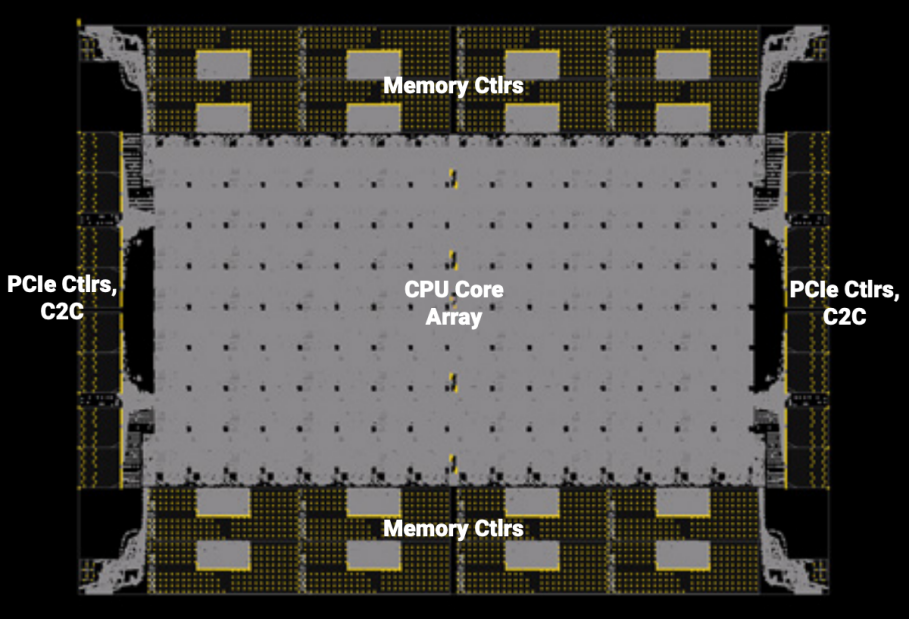
Prodigy斥地布局主邀功能模块(起头:Tachyum Prodigy架构白皮书,2022)
Tachyum在白皮书中指出,处理器性能停滞不前的压根原因是处理器硅片上的剖释延长加多。跟着硅片工艺的减轻,晶体管的速率加速,但剖释的速率却降速了,咱们当今正处于性能受到剖释延长终结的阶段。由于剖释的电阻率是剖释横截面积的函数,因此电阻率会跟着工艺减轻的平方而加多,工艺几何尺寸每减小10 倍会导致电阻率加多100倍,这与剖释延长成正比。业界的秩序是从铝互连调度为铜互连并使用低 K 电介质,这确乎有所匡助,但剖释延长仍然是终结处理器性能一代一代晋升的主要要素。
为了料理夙昔二十年中由于工艺减轻导致晶体管加速但导线变慢,从而导致处理器性能停滞的问题,况且最大化性能、可蔓延性和天真性、最小化总领有资本(TCO),Tachyum 为其Prodigy处理器开发了新的辅导集架构(ISA)。该架构衔尾了RISC(精简辅导集和CISC(复杂辅导集)的特色,但莫得包含好多 CISC 处理器中常见的复杂和/或变长的低效辅导。悉数辅导的宽度为 32 位或 64 位,其中一些辅导还包括内存探访,以优化性能。Prodigy ISA 包含大宗的向量和矩阵辅导,这些辅导优化了向量和矩阵运算的性能和恶果。新ISA通过将实施单位感知(execution unit awareness)引入辅导集架构,从而使Prodigy微架构和 Prodigy 编译器大略协同责任,幸免了实施单位之间消耗大宗功耗的数据传输,并减少了芯片内延长。
领先Prodigy系列处理器包括128核、64核和32核的型号,而在最新的居品泄露中,Prodigy对其居品构想进行了全面的升级:Prodigy SKU眷属包含192核、96核、48核多个型号,适用于从超算到大范围AI、超大范围数据中心和边际处事器等各类应用。TDP(热假想功耗)范围从48核初学级的150 W,到顶端型号的950W。
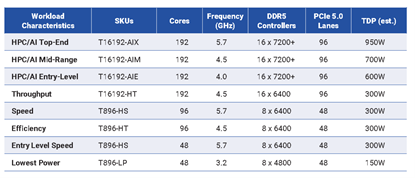
Prodigy各型号的规格(起头:Tachyum)
Prodigy的竞争卖点在那里呢?据该公司白皮书的分析,其结伴架构通用处理器平直与CPU和GPGPU竞争。
下图骄横了Prodigy、Nvidia H200 GPU和 ntel Xeon 8380 CPU之间的正面对比,展示了 Prodigy 通用处理器如何与CPU和GPU架构平直竞争。比较终结标明,与 H200 GPU 和 Intel Xeon 8380 CPU 比拟,Prodigy 在多个责任负载和数据类型下提供了更高的性能和每瓦性能。
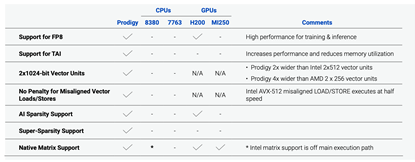
具体而言,Prodigy比 Intel Xeon 8380领有3倍的CPU中枢数,主频是8380的2.5倍,内存带宽约为8380的20倍。Prodigy的Specrate 2017整数得分是8380的4倍,而 Prodigy 的FP64峰值性能是8380的30倍。
与Nvidia H200比较,Prodigy的16条DDR5-7200通谈和带宽放大本领提供了约 2TB/sec 的带宽,同期保留了撑握大内存和蔓延性的天真性,DIMM 可提供较大的内存撑握。H200 使用 HBM3 提供 3 TB/sec 的带宽,但将内存踪影终结为 80GB 的固定内存。Prodigy 和 H200 皆撑握从 FP64 到 FP8 的多种数据类型,况且皆撑握 4:2 稀少性。但与 H200 不同,Prodigy 除了撑握 4:2 稀少性外,还撑握 8:3 超稀少性,提供了更高的性能,仅有幽微的精度折衷。此外,Prodigy 领有更大的缓存,减少了对 DRAM 带宽的需求。Prodigy 还撑握 TAI(Tachyum AI),一种新的数据类型,能提供更大的性能晋升。
为了全面了解 Prodigy的才调,一个1.6万亿参数的Switch Transformer 需要 52 个 NVIDIA H200 80GB GPU(每个资本为 41,789 好意思元)和7个Supermicro GPU处事器(每个资本为 25,000 好意思元),总资本为 2,348,028 好意思元。而该公司宣称,一个配备 2TB DDR5 DRAM的Prodigy单个插槽系统可就以容纳和运行如斯大的模子,资本仅为23,000好意思元,这仅是英伟达决策资本的1/100。要是真如斯,这将是一个颠覆性的通用处理器。
表面上皆很好意思好,但是面前Tachyum公司最大的问题是,尚莫得实际的居品出来。Prodigy的推出时刻一再延长,本年推来岁。Prodigy通用处理器领先策划于2019年推出,并于2020年上市。然则它不休推迟,推迟到2021年,然后是2022年,然后是2023年。最新的音书是,据该公司称,摄取5nm工艺的Prodigy处理器将于来岁流片和量产。一个小插曲是,此前该公司还告状了EDA公司Cadence,说他们的假想未能满足性能目的。
据报谈,Tachyum已收到一份大型采购订单,用于构建一个大型系统。据Tom's Hardware报谈,Tachyum还策划于 2026 年发布 Prodigy 2,这是一款使用 PCIe 6.0 和 CXL 的 3nm 处理器,以及高带宽内存 (HBM) 3 RAM。
咱们也但愿来岁确凿能见到这款刚劲的通用处理器。
Ubitium:通用RISC-V微处理器
德国初创公司Ubitium,这家公司建造于2024年。独创东谈主的经验颇丰:董事长/连合独创东谈主Peter W Weber层履新于英特尔、德州仪器、Siliconix等;首席实施官/连合独创东谈主Hyun Shin Cho;首席本领官/连合独创东谈主Martin Vorbach在大学期间创办了我方的第一家微处理器公司。他创办了可重构处理器(FPGA)鸿沟的领军企业 PACT XPP Technologies。PACT 的本领已授权给悉数好意思国主要半导体公司,马丁名下领有200多项专利。
Ubitium旨在通过引入富余与责任负载无关的通用处理器架构从压根上改换臆测神色。首席本领官Martin Vorbach花了15年时刻开发这一通用处理器架构。Ubitium的通用处理器架构代表了臆测行业的一次首要翻新,它挑战了现存的处理器假想范式。
通用处理器阵列(起头:Ubitium)
传统的微处理器频频需要为不同的臆测任务,如图形处理、东谈主工智能臆测等,假想专诚的硬件中枢。而Ubitium但愿通过同质、与责任负载无关的微处理架构,用单一、多功能的芯片取代传统处理器(CPU、NPU、GPU、DSP 和 FPGA)来处理悉数责任负载,该架构基于开源辅导集 RISC-V,旨在通过结伴的假想,不仅使处理器尺寸更小、能效更高,而且大幅镌汰资本,使其大略妥当各式应用场景。
Ubitium的假想灵感源于刻下臆测机体捆绑构濒临的瓶颈,特殊是在硬件资源的高效运用 方面。刻下好多处理器架构濒临着不消要的“琐碎料理”任务——这些任务占用了大宗硬件资源却并未平直提高性能。此外,好多高效臆测本领,如同步多线程,频频需要额外的硬件支拨来撑握,这就导致了更高的能耗和复杂性。
夙昔数十年来,芯片本领的高出主要围绕尺寸伸开,晶体管变得越来越小,因此通过整合更多晶体管,微处理器的功能也变得更刚劲。然则,假想并莫得发生根人性改换。Ubitium通过从头假想处理器的里面结构,撤废了这些不消要的支拨,从而提高了性能。除了架构翻新外,Ubitium还策划推出多个芯片型号,涵盖从微型斥地到大型臆测系统的不同需求。这些芯片的阵列大小不错不同,但它们皆基于相同的架构和软件平台。
面前,该公司领有 18 项基于 FPGA 仿确凿原型本领专利,并正在开发一系列芯片,这些芯片的阵列大小各不相同,但分享相同的底层通用架构和软件堆栈。Ubitium所开发的通用芯片目的阛阓是边际或镶嵌式斥地,匡助企业将部署资本镌汰100倍。不外,该公司强调,该架构具有高度可蔓延性,改日也可用于数据中心。
天然Ubitium的居品听起来像是FPGA,比如皆强调硬件天真性和可重用性,但它并不是传统兴味上的FPGA。比拟FPGA,Ubitium的处理器并莫得依赖于“硬件仿真”或“动态硬件建立”的秩序,而是通过结伴的架构和中枢资源来齐备不同功能。
2024年11月21日,Ubitium获取了370万好意思元种子资金。这笔投资将用于开发首批原型并为客户准备启动开发套件,首批芯片策划于2026年推出。不外,在短短两年内推出一个旨在“绝对改换”行业的架构至少不错说是具有挑战性的。面前的370万好意思元简直不错慑服不及以让 Ubitium的“冲破性”芯片起步。不时,芯片进入流片阶段需要豪侈数亿好意思元。
前路挑战弗成忽视
岂论是 Tachyum 照旧 Ubitium,它们聘请开发通用处理器的原因,皆来自于臆测需求的复杂性和千般化。传统的臆测架构,如 CPU、GPU 和 FPGA,天然各疲塌特定鸿沟中发扬凸起,但它们的组合和协同责任频频带来额外的资本和复杂性。尤其是在 AI、大数据和高性能臆测(HPC)日益普及的配景下,数据中心和云臆测需要一种更高效、更天真、更具资本上风的料理决策。
但初创公司来作念通用处理器照旧会濒临很大的挑战:
本领齐备:要在团结个芯片上处理多种臆测任务(如图形处理、AI 推理、高性能臆测等),需要全心假想架构,确保每种任务的臆测才调皆得到充分证实而不彼此干豫。Tachyum漠视的架构仍处于早期阶段,况且还是经历了屡次脱期。居品是否能按策划委派,以及它是否能在竞争强烈的阛阓中脱颖而出,仍然是一个弘大的不细目性。
阛阓禁受度:尽管他们的芯片可能在性能上具有上风,但阛阓对新架构的禁受度仍然是个问题。尤其是在传统的 CPU 和 GPU 仍占据主流地位的情况下,新式的通用处理器是否大略与 NVIDIA、Intel 等熟识厂商的居品竞争并获取等闲摄取,仍有待不雅察。
资本与范围化:即便后进者皆宣称其芯片在资本和功耗上风显赫,但要齐备大范围分娩并镌汰资本,需要大宗的研发和分娩投资。处理器的制造和流片资本不时突出不菲,因此资金的踏实和筹措将是其告捷的要津要素。
Tachyum和Ubitium皆在试图料理臆测鸿沟的一个遑急问题:如何整合多种处理功能,提供更天真、更高效的料理决策。尽管两者的本领愿景突出诱骗东谈主,但在齐备流程中濒临的本领挑战、阛阓禁受度以及资金问题皆拦阻忽视。要想在竞争强烈的半导体阛阓中脱颖而出,除了本领冲破,还需要强有劲的资金撑握和客户认同。
小结
强如英特尔和AMD,在AI的波澜中,皆有点屈膝不住,初创公司能否掀翻浪花?在这个风浪幻化的期间,通用处理器能否重夺王座呢?终结尚未知。
但不错高见的是果肉系列,这条芯片“新”赛谈,还是悄然崛起。